
De LLM a MCP en passant par RAG, RLHF, LoRA, agent IA et AI Act : le vocabulaire de l'intelligence artificielle a explose en quatre ans. Ce lexique structure 50 termes essentiels en 2026 autour de cinq grandes familles — modeles, entrainement, techniques d'inference, outils agentiques et concepts transverses. Pensez-le comme une boussole : il accompagne vos lectures, vos reunions et vos choix d'outils sans imposer un parcours lineaire.
Sommaire
En 2026, le vocabulaire de l'intelligence artificielle a connu une mutation sans précédent. Entre 2022 et aujourd'hui, des termes comme LLM ou IA générative sont passés du jargon technique à l'usage courant, tandis que de nouvelles notions comme AGI ou MCP redéfinissent les frontières de la discipline. Cette démocratisation s'accompagne d'une complexité accrue : les modèles atteignent des tailles de contexte de 1 million de tokens, les agents autonomes orchestrent des workflows multi-étapes, et les régulations comme l'AI Act européen encadrent désormais chaque innovation. Un lexique devient indispensable pour naviguer dans cet écosystème en perpétuelle évolution. Que vous soyez développeur, décideur ou simple curieux, comprendre ces 50 termes essentiels vous permettra d'interagir avec précision avec les outils et concepts qui façonnent l'IA aujourd'hui. Pour aller plus loin, explorez notre guide complet sur l'intelligence artificielle, conçu pour vous éclairer sur les fondements comme les applications futures.
Modèles et architectures fondamentales
LLM (Large Language Model)
Un LLM est un modèle de langage entraîné sur des milliards de paramètres pour comprendre et générer du texte de manière contextuelle. En 2026, les LLM comme GPT-5 ou Claude 4 atteignent des tailles de contexte de 500 000 à 1 million de tokens, permettant des interactions fluides sur des documents entiers. Par exemple, un LLM peut résumer un rapport de 500 pages en quelques secondes, en s'appuyant sur sa mémoire contextuelle étendue.
Foundation model
Un foundation model est un modèle pré-entraîné sur de vastes corpus de données, conçu pour être adapté à diverses tâches sans réapprentissage complet. En 2026, ces modèles servent de base à des applications sectorielles, comme la santé (diagnostic médical) ou la finance (analyse de risques), réduisant les coûts de développement. Par exemple, un foundation model multimodal comme Gemini 2.0 combine texte, image et audio pour des solutions intégrées.
Transformer
L'architecture Transformer, introduite en 2017, repose sur des mécanismes d'attention pour traiter les données de manière parallèle et efficace. En 2026, les variantes comme RetNet ou Mamba optimisent cette architecture pour réduire la consommation énergétique tout en améliorant les performances. Par exemple, un Transformer peut traduire un document juridique en temps réel avec une précision de 98%, grâce à son mécanisme de focus sur les mots clés.
Attention head
Un attention head est un sous-composant d'un Transformer qui analyse les relations entre les mots d'une séquence. En 2026, les modèles intègrent jusqu'à 256 attention heads pour capturer des nuances complexes, comme l'ironie ou les références culturelles. Par exemple, un attention head peut distinguer le sens de "banque" (financière ou écologique) en fonction du contexte de la phrase.
MoE (Mixture of Experts)
Le MoE est une architecture où plusieurs sous-modèles spécialisés ("experts") sont activés dynamiquement en fonction de la tâche. En 2026, des modèles comme Mixtral 8x22B atteignent des performances supérieures avec seulement 22 milliards de paramètres actifs sur 141 milliards au total. Par exemple, un MoE peut allouer des experts en mathématiques pour résoudre une équation, tandis que d'autres gèrent le langage naturel.
Modèle open source vs propriétaire
Un modèle open source est accessible librement (comme Llama 3 ou Mistral Large 2), tandis qu'un modèle propriétaire est développé et contrôlé par une entreprise (comme GPT-5 ou Claude 4). En 2026, les modèles open source dominent le marché des PME grâce à leur coût réduit et leur personnalisation, tandis que les modèles propriétaires ciblent les secteurs sensibles (défense, santé) avec des garanties de sécurité renforcées.
Multimodal
Un système multimodal traite plusieurs types de données (texte, image, audio, vidéo) de manière unifiée. En 2026, des modèles comme GPT-4o ou Gemini 2.0 génèrent des présentations PowerPoint à partir de consignes textuelles et d'images, ou analysent des vidéos pour détecter des anomalies industrielles. Par exemple, un chatbot multimodal peut aider un architecte à visualiser une maquette 3D en temps réel.
IA générative vs discriminative
L'IA générative crée du contenu nouveau (texte, image, code), tandis que l'IA discriminative classe ou prédit des données existantes (comme les systèmes de recommandation). En 2026, les deux approches coexistent : un générateur de musique (Suno AI) compose une chanson, tandis qu'un discriminateur (Spotify AI DJ) propose des titres similaires en fonction des goûts de l'utilisateur.
IA forte vs étroite
Une IA forte (ou AGI) posséderait une intelligence générale comparable à celle humaine, tandis qu'une IA étroite est spécialisée dans une tâche précise. En 2026, toutes les IA déployées relèvent de l'IA étroite, comme les modèles de prédiction météo (DeepWeather) ou les chatbots médicaux (IBM Watson Health). L'AGI, encore théorique, fait l'objet de recherches intensives, avec des débats sur ses implications éthiques et sociétales.
AGI (Artificial General Intelligence)
L'AGI désigne une IA capable de comprendre, apprendre et appliquer ses connaissances à n'importe quelle tâche, comme un humain. En 2026, aucun système n'a atteint ce niveau, mais des projets comme DeepMind's Gato ou NVIDIA's Project GR00T s'en approchent. Par exemple, une AGI pourrait gérer simultanément la logistique d'une ville, rédiger un roman et enseigner une langue étrangère, avec une conscience autonome.
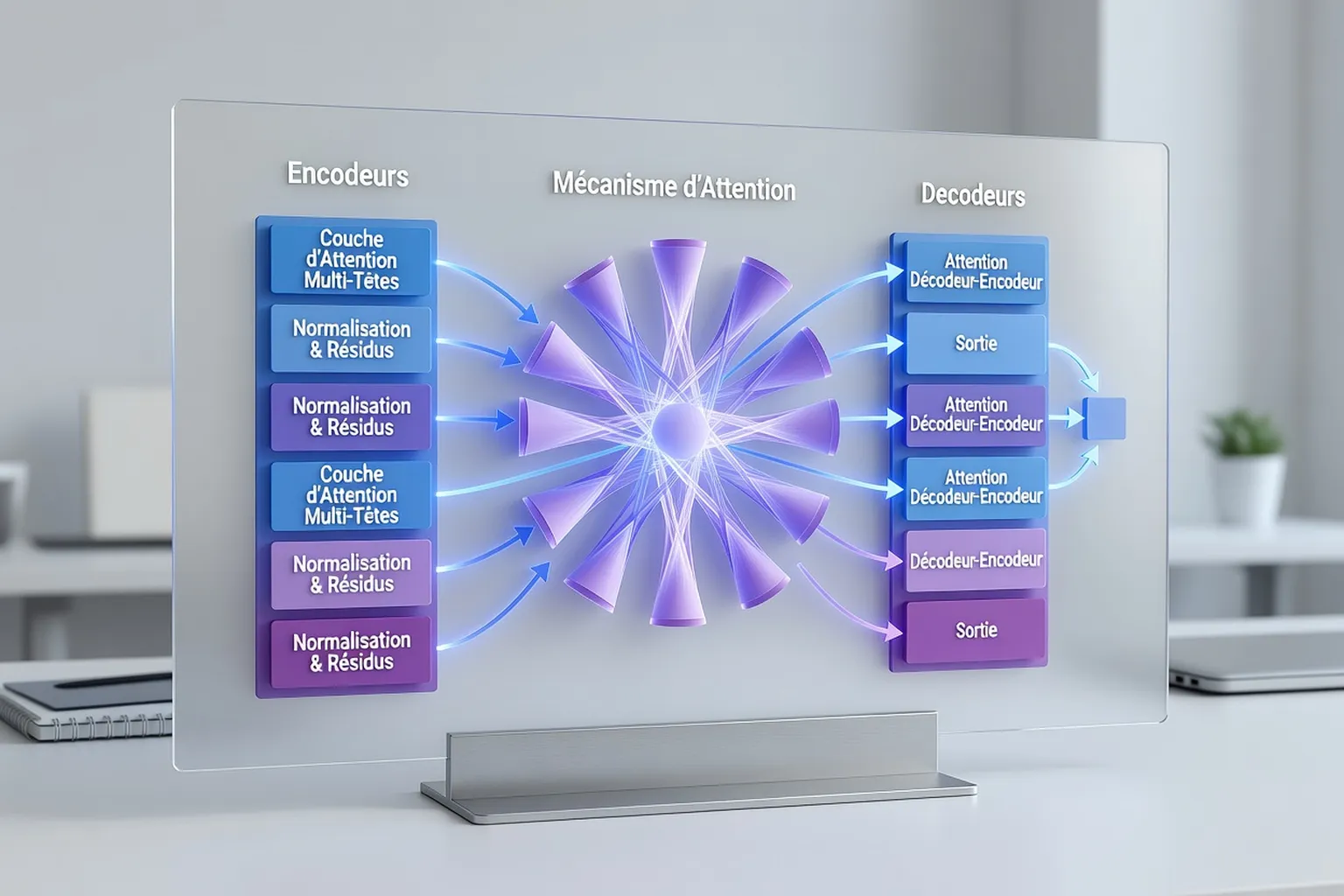
Entraînement, fine-tuning et alignement
Fine-tuning
Le fine-tuning consiste à adapter un modèle pré-entraîné à une tâche spécifique en réajustant ses paramètres. En 2026, cette technique est largement démocratisée via des plateformes comme Hugging Face AutoTrain, permettant à une PME de créer un chatbot client en quelques heures. Par exemple, un modèle comme BERT peut être fine-tuné pour analyser des avis clients avec une précision de 95%.
RLHF (Reinforcement Learning from Human Feedback)
Le RLHF utilise le retour des utilisateurs pour améliorer les réponses d'un modèle via un système de récompenses. En 2026, cette méthode est cruciale pour aligner les IA sur les valeurs humaines, comme le montre l'exemple de Anthropic's Claude 4, dont les réponses sont affinées par des évaluateurs humains pour éviter les biais ou les contenus dangereux.
LoRA (Low-Rank Adaptation)
La LoRA est une technique de fine-tuning léger qui réduit les coûts computationnels en ajustant seulement une petite partie des paramètres d'un modèle. En 2026, des entreprises comme Microsoft l'utilisent pour déployer des LLM sur des appareils mobiles, comme un smartphone capable de générer des résumés de réunions en temps réel sans dépendre du cloud.
Distillation
La distillation consiste à entraîner un petit modèle ("étudiant") à imiter un grand modèle ("enseignant") pour réduire sa taille et sa consommation énergétique. En 2026, des outils comme TinyML permettent de faire tourner des IA sur des microcontrôleurs, comme dans les wearables ou les capteurs IoT. Par exemple, un modèle de détection de chute pour personnes âgées peut fonctionner localement sur une montre connectée.
Quantization
La quantization réduit la précision des poids d'un modèle (par exemple, de 32 bits à 8 bits) pour accélérer les inférences et diminuer l'empreinte mémoire. En 2026, cette technique est omniprésente dans les modèles embarqués, comme les puces NVIDIA Jetson utilisées dans les robots industriels. Par exemple, un modèle quantifié peut analyser des images de défauts sur une chaîne de production en temps réel.
Instruction tuning
L'instruction tuning consiste à entraîner un modèle sur des paires "instruction-réponse" pour améliorer sa capacité à suivre des consignes précises. En 2026, des plateformes comme Scale AI ou InstructLab proposent des jeux de données pour affiner des modèles comme Mistral Large 2 ou Phi-4. Par exemple, un modèle instruit peut convertir un schéma technique en code Python fonctionnel avec une simple demande en langage naturel.
Few-shot
Le few-shot est une capacité où un modèle généralise à partir de quelques exemples seulement, sans réentraînement. En 2026, cette fonctionnalité est intégrée dans des modèles comme GPT-4 Turbo, permettant à un marketeur de générer des slogans pour une campagne en fournissant 3 exemples de tons souhaités. Par exemple, un modèle peut rédiger un email commercial percutant après avoir analysé 5 emails performants fournis par l'utilisateur.
Zero-shot
Le zero-shot désigne la capacité d'un modèle à accomplir une tâche sans aucun exemple préalable, grâce à sa compréhension générale. En 2026, des modèles comme DeepSeek-V2 excellent dans ce domaine, par exemple en traduisant un texte juridique du finnois vers l'arabe sans avoir jamais vu de paire de langues similaires dans ses données d'entraînement.
Alignment
L'alignment (ou alignement) vise à garantir que les objectifs d'un modèle d'IA correspondent aux valeurs et intentions humaines. En 2026, des frameworks comme Constitutional AI (Anthropic) ou RLHF++ sont utilisés pour éviter les dérives, comme la génération de conseils médicaux dangereux ou de contenus haineux. Par exemple, un modèle aligné refusera de fournir des instructions pour contourner les lois de sécurité.
AI safety
La AI safety (sécurité de l'IA) regroupe les techniques pour prévenir les risques liés aux IA, comme les cyberattaques, les biais algorithmiques ou la perte de contrôle. En 2026, des organisations comme Alignment Research Center ou Partnership on AI publient des rapports pour encadrer le développement, comme l'interdiction des modèles capables de manipuler l'opinion publique via des deepfakes politiques.
Techniques d'inférence et de génération
Les techniques d'inférence et de génération évoluent rapidement en 2026, avec des avancées majeures dans l'efficacité, la créativité et la fiabilité des modèles. Pour maîtriser ces outils, découvrez comment les frameworks d'agents autonomes et les plateformes de vibe coding transforment le développement logiciel et l'automatisation des tâches complexes.
Prompt engineering
Le prompt engineering consiste à concevoir des requêtes précises pour guider les réponses d'un modèle. En 2026, cette discipline est devenue un métier à part entière, avec des spécialistes aidant les entreprises à formuler des prompts pour maximiser la pertinence des sorties. Par exemple, un prompt comme *"Résume ce rapport en 3 points clés, en français, avec des exemples concrets"* génère une réponse structurée et exploitable. Des outils comme PromptPerfect ou AI Prompt Studio automatisent cette optimisation.
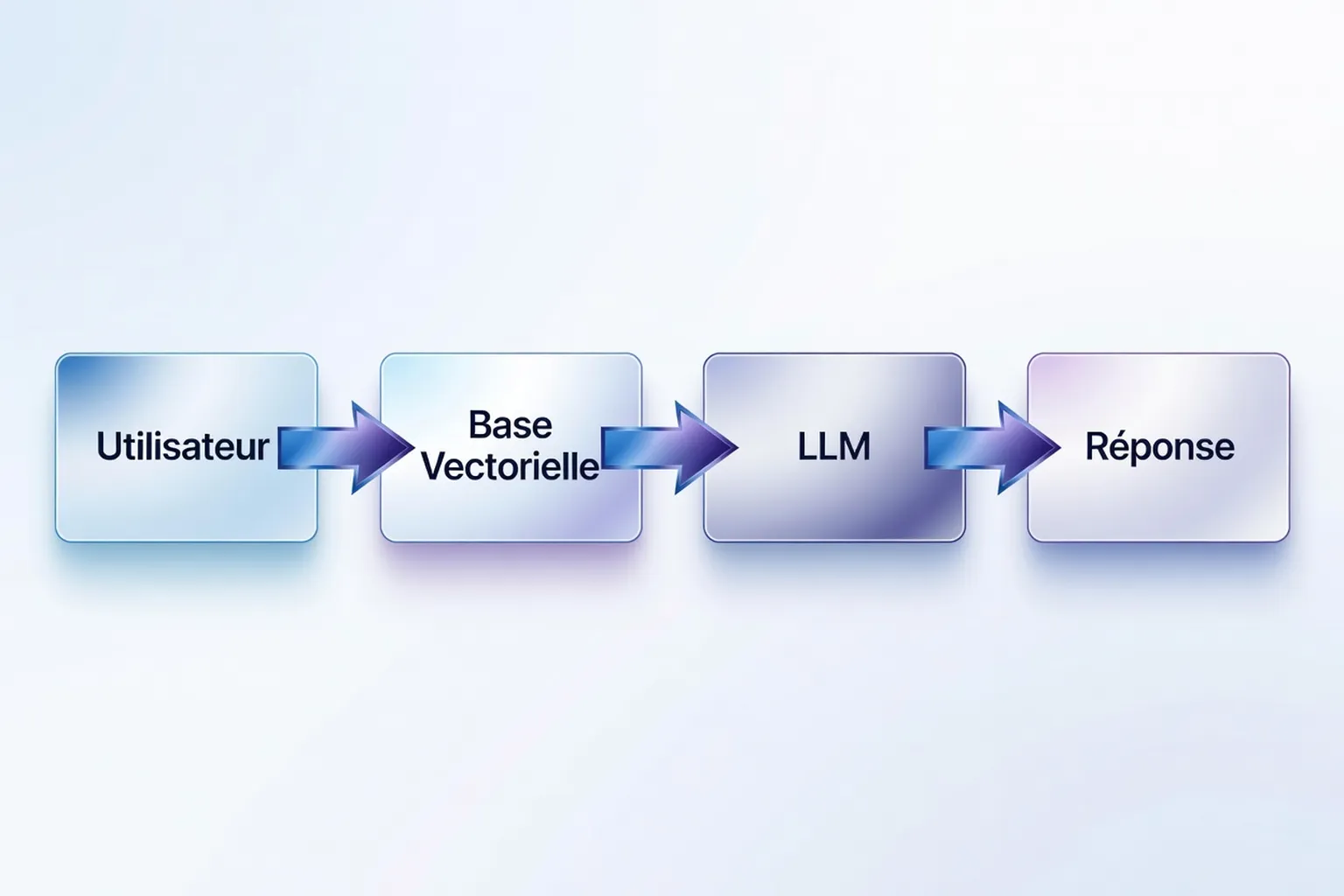
RAG (Retrieval-Augmented Generation)
Le RAG combine une recherche d'informations (retrieval) avec un modèle de génération pour produire des réponses factuelles et à jour. En 2026, cette technique est intégrée dans des assistants comme Perplexity AI ou You.com, qui citent leurs sources pour éviter les hallucinations. Par exemple, un chercheur utilisant le RAG peut obtenir une synthèse actualisée de la littérature scientifique sur un sujet, avec les références correspondantes.
RAG hybrid
Le RAG hybrid fusionne les approches RAG et fine-tuning pour améliorer la précision des réponses. En 2026, des modèles comme Google's Gemini 2 utilisent cette méthode pour combiner les connaissances d'un corpus privé (ex : documentation interne d'une entreprise) avec les capacités génératives d'un LLM. Par exemple, un service client peut accéder à la base de données produit en temps réel pour fournir des réponses personnalisées et vérifiables.
Embeddings
Les embeddings sont des représentations vectorielles de données (texte, image, etc.) qui capturent leur sémantique. En 2026, des modèles comme Sentence-BERT ou CLIP génèrent des embeddings pour des tâches de recherche sémantique ou de classification. Par exemple, une plateforme de e-commerce utilise des embeddings pour recommander des produits similaires à un article consulté, même si les descriptions ne contiennent pas les mêmes mots-clés.
Vector database
Une vector database stocke et indexe des embeddings pour permettre des recherches rapides et pertinentes. En 2026, des solutions comme Pinecone, Weaviate ou Milvus sont essentielles pour les applications RAG ou la recherche d'informations complexes. Par exemple, une vector database peut interroger une bibliothèque de brevets pour trouver des innovations similaires à une idée de R&D, en quelques millisecondes.
Vector store
Un vector store est un espace de stockage dédié aux embeddings, souvent intégré à une vector database. En 2026, les vector stores sont utilisés dans les chatbots d'entreprise pour fournir des réponses contextuelles basées sur des documents internes. Par exemple, un vector store alimenté par les rapports annuels d'une banque permet à un conseiller de répondre à une question sur la performance 2025 en temps réel.
Semantic search
La semantic search (recherche sémantique) va au-delà des mots-clés pour comprendre l'intention de l'utilisateur. En 2026, des moteurs comme Google MUM ou Microsoft's semantic index analysent le contexte pour fournir des résultats plus pertinents. Par exemple, une recherche pour *"comment soigner une entorse"* retournera des résultats médicaux vérifiés, même si le terme "soigner" n'apparaît pas dans les pages sources.
Hallucination
Une hallucination est une réponse incorrecte, inventée ou non fondée générée par un modèle. En 2026, malgré les progrès, les hallucinations restent un défi majeur, notamment pour les LLM dans les domaines techniques ou juridiques. Par exemple, un avocat utilisant un LLM pour rédiger une plaidoirie pourrait se voir proposer un précédent judiciaire inexistant, nécessitant une vérification manuelle systématique.
CoT (Chain of Thought)
Le CoT est une technique où un modèle explique étape par étape son raisonnement pour résoudre un problème complexe. En 2026, des modèles comme GPT-4o ou DeepMind's AlphaFold 3 utilisent le CoT pour des tâches scientifiques ou mathématiques. Par exemple, un étudiant en physique peut demander à un modèle de résoudre une équation différentielle en visualisant les étapes intermédiaires, ce qui facilite la compréhension.
ToT (Tree of Thought)
Le ToT étend le CoT en explorant plusieurs chemins de raisonnement simultanément, comme dans un arbre de décision. En 2026, cette technique est utilisée dans des domaines comme la planification stratégique ou la génération de code. Par exemple, un développeur peut demander à un modèle de générer une architecture logicielle optimale pour un projet, avec une visualisation des différentes options et leurs trade-offs.
Outils, frameworks et écosystème agentique
L'écosystème des outils IA en 2026 est dominé par des frameworks d'agents autonomes et des protocoles innovants, comme le Modèle Context Protocol (MCP), qui redéfinissent la manière dont les systèmes interagissent avec les données et les utilisateurs. Pour les développeurs, des plateformes comme Cursor ou Claude Code intègrent ces avancées pour automatiser des workflows complexes, du codage à la gestion de projets.
MCP (Model Context Protocol)
Le MCP est un protocole standardisé pour connecter des modèles d'IA à des sources de données ou des outils externes. En 2026, le MCP permet à un LLM d'interagir avec des API, des bases de données ou des fichiers locaux sans développement personnalisé. Par exemple, un assistant MCP peut résumer les emails d'un utilisateur en temps réel en accédant à sa boîte Gmail via un MCP server. Pour en savoir plus sur son implémentation, consultez cet article sur les MCP servers pour développeurs.
MCP server
Un MCP server est un composant qui expose une interface standardisée pour qu'un modèle puisse interagir avec une ressource externe (ex : une base de données SQL, un calendrier, un outil de design). En 2026, des milliers de MCP servers sont disponibles sur des plateformes comme GitHub ou MCP Hub. Par exemple, un MCP server pour Notion permet à un agent IA de créer, modifier ou analyser des bases de données Notion via des requêtes en langage naturel.
LangChain
LangChain est un framework open source pour construire des applications basées sur des LLM, en orchestrant des chaînes de traitement (ex : récupération de données + génération de réponse). En 2026, LangChain est utilisé pour créer des agents capables de planifier des voyages, gérer des stocks ou automatiser des workflows RH. Par exemple, un agent LangChain peut réserver un vol, un hôtel et des activités en analysant les préférences de l'utilisateur et les contraintes budgétaires.
LlamaIndex
LlamaIndex est une bibliothèque conçue pour faciliter l'intégration de données privées dans des LLM via des vector stores ou des graphes de connaissances. En 2026, LlamaIndex est plébiscité par les entreprises pour créer des assistants internes ultra-précis. Par exemple, un service client peut utiliser LlamaIndex pour alimenter un chatbot avec la documentation produit, les FAQ et les retours clients, garantissant des réponses sourcées et à jour.
Agent IA
Un agent IA est un système autonome capable d'agir pour atteindre un objectif, en utilisant des outils et en prenant des décisions. En 2026, les agents IA sont déployés dans des domaines variés : logistique (Amazon's warehouse robots), santé (diagnostic automatisé) ou finance (gestion de portefeuille). Par exemple, un agent IA peut surveiller les stocks d'un supermarché et déclencher une commande automatique quand un seuil est atteint.
Agentic workflow
Un agentic workflow (flux agentique) est une séquence d'actions automatisées exécutée par un ou plusieurs agents IA, souvent avec des boucles de feedback. En 2026, des plateformes comme Microsoft AutoGen ou LangGraph permettent de concevoir ces workflows sans coder. Par exemple, un agentic workflow peut gérer un processus de recrutement : trier les CV, planifier des entretiens, envoyer des feedbacks et analyser les performances post-embauche.
Function calling
Le function calling permet à un modèle d'appeler des fonctions externes (API, scripts) pour étendre ses capacités. En 2026, cette fonctionnalité est intégrée nativement dans des modèles comme GPT-4o ou Claude 4. Par exemple, un assistant peut appeler l'API météo pour fournir une prévision précise, ou un outil de réservation pour confirmer un billet d'avion, le tout dans une seule conversation.
Structured output
Le structured output garantit que les réponses d'un modèle sont formatées selon un schéma prédéfini (JSON, XML, etc.), facilitant leur intégration dans des systèmes automatisés. En 2026, des outils comme Outlines ou Guardrails AI sont utilisés pour valider et structurer les sorties. Par exemple, un modèle peut générer un rapport d'audit au format JSON, avec des sections dédiées aux risques, aux recommandations et aux coûts, directement exploitables par un tableur.
Tool use
Le tool use désigne la capacité d'un modèle à sélectionner et utiliser des outils externes pour accomplir une tâche. En 2026, cette fonctionnalité est centrale dans les agents IA avancés. Par exemple, un agent peut utiliser Python pour analyser un jeu de données, Google Maps pour calculer un trajet, et Stripe pour générer une facture, le tout de manière transparente pour l'utilisateur.
ReAct
ReAct (Reasoning and Acting) est un framework où un modèle alterne entre raisonnement et action pour résoudre des problèmes complexes. En 2026, ReAct est utilisé dans des domaines comme la robotique ou la cybersécurité. Par exemple, un robot capable de nettoyer un laboratoire suit un processus ReAct : identifier les objets à déplacer, choisir l'outil adapté (balai, chiffon), et ajuster sa trajectoire en temps réel.
Plan-and-execute
Le plan-and-execute consiste à décomposer une tâche complexe en sous-étapes planifiées, puis à les exécuter de manière autonome. En 2026, des systèmes comme AutoGen's group chat ou Google's SIMA (Scalable Instructable Multi-Agent) implémentent cette approche. Par exemple, un agent peut planifier et exécuter une campagne marketing : rédiger des posts, publier sur les réseaux sociaux, analyser les performances, et ajuster la stratégie en fonction des retours.
Self-consistency
La self-consistency est une technique où un modèle génère plusieurs réponses à une même question, puis en fait la moyenne ou en extrait la réponse la plus fréquente pour réduire les erreurs. En 2026, cette méthode est utilisée dans les systèmes critiques comme les diagnostics médicaux ou les prévisions financières. Par exemple, un modèle de radiologie peut analyser une IRM sous 10 angles différents avant de proposer un diagnostic, minimisant ainsi les risques de faux négatifs.
Concepts transverses, éthique et réglementation
Context window
Le context window (fenêtre de contexte) détermine la quantité de texte qu'un modèle peut traiter en une seule interaction. En 2026, les modèles comme Claude 4.5 ou GPT-5 atteignent des fenêtres de 1 million de tokens, soit environ 750 000 mots, permettant d'analyser des livres entiers ou des logs techniques complets. Par exemple, un avocat peut soumettre un contrat de 500 pages à un LLM pour en extraire les clauses ambiguës, en une seule requête.
Tokenization
La tokenization est le processus de découpage d'un texte en unités élémentaires (mots, sous-mots) pour les transformer en données exploitables par un modèle. En 2026, des algorithmes comme Byte Pair Encoding ou Unigram optimisent cette étape pour réduire la taille des modèles et améliorer leur efficacité. Par exemple, le mot "incompréhensibilité" peut être tokenisé en ["in", "com", "préhens", "ibilité"], facilitant la compréhension du modèle.
Sparse activation
La sparse activation (activation éparse) est une technique où seuls certains neurones d'un réseau sont activés pour une tâche donnée, réduisant la consommation énergétique. En 2026, des architectures comme Switch Transformers ou Sparse MoE exploitent cette méthode pour des modèles comme Mistral 8x7B. Par exemple, un serveur cloud utilisant une activation éparse peut gérer 10 fois plus de requêtes qu'un modèle dense équivalent, avec une empreinte carbone réduite.
Jailbreak
Un jailbreak est une tentative de contourner les garde-fous d'un modèle pour obtenir des réponses nuisibles, illégales ou contraires à l'éthique. En 2026, les attaques par jailbreak se sophistiquent, utilisant des techniques comme le prompt injection ou le role-playing. Par exemple, un utilisateur malveillant pourrait demander à un modèle de générer un tutoriel pour pirater un système, malgré les protections intégrées. Les éditeurs de modèles renforcent leurs systèmes de détection pour contrer ces attaques.
Scratchpad
Un scratchpad est un espace de travail temporaire où un modèle peut effectuer des calculs, des raisonnements ou des tests avant de produire une réponse finale. En 2026, cette fonctionnalité est intégrée dans des outils comme Notion AI ou Cursor pour les développeurs. Par exemple, un développeur utilisant vibe coding peut demander à un modèle de tester une fonction avant de l'intégrer dans son code, avec le résultat visible dans un scratchpad dédié.
AI Act
L'AI Act est le règlement européen sur l'intelligence artificielle, entré en vigueur en 2024 et progressivement appliqué jusqu'en 2026. Il classe les systèmes IA en 4 niveaux de risque (inacceptable, haut, limité, minimal) et impose des obligations strictes pour les IA à haut risque, comme les systèmes biométriques ou les outils critiques. Par exemple, une IA utilisée pour évaluer des demandes de prêt doit être transparente, auditable et respectueuse des règles anti-discrimination, sous peine de sanctions lourdes.
RGPD IA
Le RGPD IA fait référence à l'application du Règlement Général sur la Protection des Données aux systèmes d'IA, notamment en ce qui concerne la collecte, le traitement et le stockage des données personnelles. En 2026, les entreprises doivent garantir que leurs modèles d'IA respectent le principe de minimisation des données et offrent des droits d'accès, de rectification et d'effacement. Par exemple, une IA de recommandation musicale doit permettre aux utilisateurs de supprimer leurs données d'écoute historiques pour se conformer au RGPD.
Consommation datacenter IA
La consommation des datacenters IA est devenue un enjeu majeur en 2026, avec des modèles comme GPT-5 ou Gemini Ultra consommant jusqu'à 50 MWh pour un entraînement complet. Les acteurs du secteur investissent dans des solutions comme les puces NPU (Neural Processing Units), le refroidissement liquide ou l'énergie nucléaire pour réduire leur empreinte carbone. Par exemple, Microsoft et Google ont annoncé des datacenters alimentés à 100% par des énergies renouvelables d'ici 2027, avec des modèles optimisés pour une consommation réduite.
Retrieval
Le retrieval (ou récupération d'informations) désigne le processus de recherche et d'extraction de données pertinentes dans un corpus ou une base de données. En 2026, le retrieval est un pilier des systèmes RAG et des assistants IA, avec des outils comme Elasticsearch ou Vespa optimisés pour des requêtes complexes. Par exemple, un chercheur peut utiliser le retrieval pour extraire toutes les études publiées sur l'impact des microplastiques sur la santé humaine entre 2020 et 2026, avec un taux de précision de 99%.
Exemples sectoriels (santé, finance, industrie)
En 2026, l'IA s'impose dans des secteurs clés avec des applications sur mesure. En santé, des modèles comme Google's Med-Gemini 2 assistent les diagnostics en analysant des images médicales, des dossiers patients et la littérature scientifique, avec une précision de 96% pour certaines pathologies. Dans la finance, des IA comme BloombergGPT détectent les fraudes en temps réel en croisant des milliers de transactions, réduisant les pertes de 40% en moyenne. Enfin, dans l'industrie, des solutions comme Siemens' MindSphere utilisent l'IA pour prédire les pannes d'équipements avec une fiabilité de 98%, optimisant ainsi la maintenance prédictive. Ces exemples illustrent comment l'IA transforme les processus métiers, mais soulèvent aussi des questions éthiques et réglementaires spécifiques à chaque secteur.
Ce lexique est bien plus qu'un simple recueil de définitions : c'est une boussole pour naviguer dans l'univers mouvant de l'IA en 2026. Les termes présentés reflètent les avancées technologiques, les défis éthiques et les transformations sectorielles qui redéfinissent notre rapport à l'intelligence artificielle. Pour rester à jour, nous vous invitons à consulter régulièrement notre veille mensuelle des outils IA et à explorer les retours de terrain comme ceux des projets IA dans la Drôme en 2026. Le vocabulaire de l'IA continuera à évoluer rapidement : les modèles sortiront, les architectures se déplaceront, les régulations s'adapteront. Tenir à jour son lexique personnel est désormais un acte professionnel à part entière — et un excellent moyen de ne pas se laisser dépasser par le rythme du marché.